




Ghost in the machine
Of all the consumer applications for artificial intelligence, proponents have focused their efforts on photography first. Results: mixed.
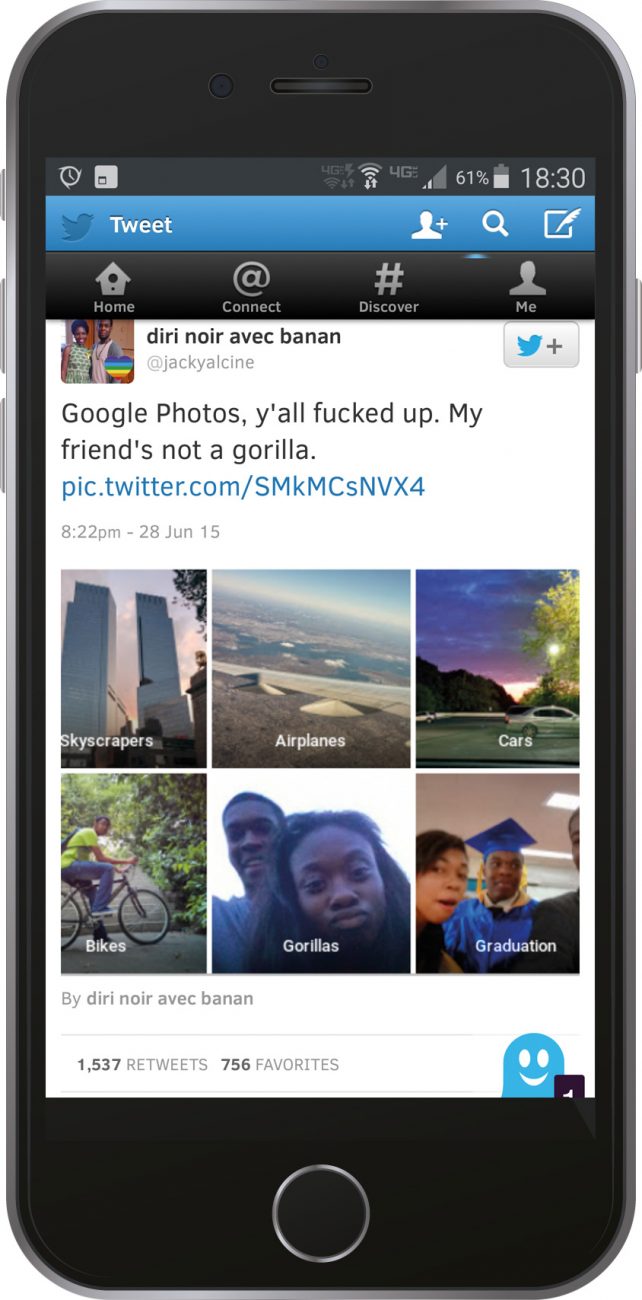
At lunchtime, on June 29, 2015, Jacky Alciné was thumbing through photos on his phone, browsing them using a new feature in Google Photos that automatically labels images by subject. It had correctly identified pictures of skyscrapers, airplanes, cars and bikes within the thousands of photographs in his collection. It had also spotted pictures of a graduation.
Alciné, a computer programmer, was impressed with the performance of the software, until he scrolled down to a category that the app had labeled ‘Gorillas’, into which it had collected images of his African-American friends. Alarmed, he tweeted a screenshot, with the message, “Google Photos, y’all f*cked up. My friend’s not a gorilla.” Later, with an acknowledgement that he understood something of the principles of machine learning, he added, “Like I understand HOW this happens; the problem is moreso on the WHY.”
Within 90 minutes, Yonatan Zunger, a Google+ engineer and Chief Architect of Photos, replied to the tweet in more candid terms; “Holy f*ck… This is 100% Not OK.” The ‘Gorillas’ label was removed overnight, and Google Photos publicists went into overdrive hosing down the public outrage.
Meanwhile, a more useful discussion was taking place on Twitter, where Zunger admited that the company was still working on “long-term fixes” for “dark-skinned faces”, and admitted that, until recently, Photos was “confusing white faces with dogs and seals… Machine learning is hard.”
Google is at the forefront of artificial intelligence and machine learning, building the technology into speech and photo recognition as well as natural language processing for its search engine. Of all of the potential consumer applications for this entry-level AI, Google settled on photography as an early and achievable problem to solve.
Three months ago, Apple followed suit, bringing machine learning to its Photos app, which ‘re-surfaces’ images and automatically creates albums based on events, people and places, in a bid to make the surplus of images easier to organise and navigate. And the problem is getting bigger by the year—in 2015, we took one trillion photos, on top of the 2.7 trillion we already had stored.
Machine learning has a ways to go. Early adopters complained that Apple Photos labelled a dog as a tie, and more strangely, an anemone as Barbara Streisand. Some users have complained of their phones chugging under the processing weight of the facial recognition, and getting hot. Others have noticed with considerable anxiety that Apple is surfacing old porn lurking on their desktop hard drives. Which begs another question—do we really want all of our memories remembered?
Images of deceased relatives have spooked some users, while Facebook created a funky album with an up-beat backing track out of scenes of a car accident that were taken for insurance purposes.
If machines can tell one face from another, acculturating themselves to ideas of timing and propriety may yet be some time off.
But none of these processing fails obscure the utility of the technology for consumers, and it’s only a matter of time before the great minds of machine learning get let loose in the relatively more structured databases of photography held in public institutions that have for decades been diligently digitising their collections. Bots could re-write history based on their finds, and certainly turn up images lost (or hidden) for generations.
Which brings us back to the astute observation of the African-American programmer who discovered Google’s first faux pas. Engineers have long been focused on the overwhelming technical obstacles presented by how to apply machine learning to photography. The more pressing concern for Alciné and the rest of us is why machine learning should be the solution, and what that might mean for the future of photography.







